python3 默認編碼是unicode
GBK 可兼容GB2312
unicode 存英文和中文都是兩個字節
unicode 萬國碼
GBK <-> Unicode <-> UTF-8 中間必須透過unicode轉換
f = open rb wb ab 打開的是二進制格式
f = open('txt.txt','rb',encoding='utf-8')
| 函數 |
註解 |
| append |
增 |
| pop |
刪除最後 |
| del |
指定刪除 |
| sort |
排序 |
| reverse |
倒轉 |
| extend |
延伸 |
| 函數 |
註解 |
| get |
查 |
| in |
"字串" in dict , 回應 True or False |
| keys |
印出字典所有key |
| values |
印出字典所有vlaue |
| setdefault('f', 'friend') |
key沒有f所以創建一個key value |
| update |
修改已有的,新增沒有的,進行合併 |
| items |
將字典變成列表 |
| fromkeys([1, 2, 3], ['abc', ['a', 'b', 'c'], 123]) |
給前面三個key一個對應的value“位址” |
| 函數 |
註解 |
| capitalize() |
首字母大寫 |
| center(50,'*') |
美化打印 |
| ljust(50,'-') |
補齊50個字 |
| endswith('on') |
檢查結尾是否為這個字串,回傳True or False |
| strings[strings.find('name'):] |
查找並切片 |
| format_map({'name':'Leon','age':30}) |
format 使用字典去正規化 |
| join(['1','2','3','4'])) |
添加列表內的值到字串上 |
| lstrip() |
左換行符號和空格符號移除 |
| rstrip() |
右換行符號移除 |
| strip() |
左右空格和換行符號都移除 |
| replace('a','A',2) |
可指定置換次數 |
| split(' ') |
用空格來分類 |
a = maketrans('abcdefg','1234567') #建立一組替換規則
translate(a) #套用規則
| 函數 |
註解 |
| index |
索引查詢 |
| count |
計算出現次數 |
| 函數 |
註解 |
| open(file,'r') |
讀檔案 |
| open(file,'w') |
寫檔案 |
| open(file,'a') |
加寫檔案 |
f = open(file,'r')
f.readline() #讀取行
f.tell() #顯示光標位置
f.seek() #讓光標回到0
f.close() #關閉檔案
| 另一開檔方法 |
註解 |
| with open(file,'r') as f: |
這種寫法不需要下f.close() |
雙開檔案 一讀一寫
with open('file_p', 'r') as f, \
open('file_p_修改', 'w') as f_new:
set1 = set([1,2,3,4,5]) #一個集合
| 函數 |
另一種相同寫法 |
註解 |
| set1.intersection(set_2) |
set1 & set2 |
交集 |
| set1.union(set_2) |
list_1 ` |
` list_2 |
| set1.difference(set2) |
set1 - set2 |
差集 我有你沒有 |
| set3.issubset(set1) |
|
子集 |
| set1.issuperset(set3) |
|
父集 |
| set1.symmetric_difference(set2) |
set1 ^ set2 |
對稱差集 |
| set1.isdisjoint(set4) |
|
沒有任何交集就回傳true |
| set1.add(999) |
|
添加 |
| set1.update([777,8888,99999]) |
|
多值添加 |
| set1.pop() |
|
隨機刪除 |
| set1.remove(777) |
|
如果裡面沒有這個東西會報錯,有就刪除 |
| set1.discard('333') |
|
如果有這個就刪除,沒有也不會報錯 |
| 函數 |
註解 |
| argv |
接受cmd的訊息 |
| getdefaultencoding() |
獲取當前預設的解碼 |
| decode('gbk') |
編碼"簡體" |
| encode('utf-8') |
解碼"utf-8" |
| path |
系統內的環境變數路徑 |
|
print(argv)
>>>['script.py','1','2','3','4']
argv[1]
>>>1
#宣告函數
def foo():
print('123')#裝飾器
def decorator(func):
def warpper(*args, **kwargs):
ccc = 0
func(*args, **kwargs)
ddd = 0
return warpper
@decorator
def func1():
aaa = 0
bbb = 0
func1()otherdeco = decorator(func1) #另一種裝飾的用法
| 裝飾後的func()執行順序 |
內容 |
| 1 |
func() |
| 2 |
ccc = 0 |
| 3 |
aaa = 0 |
| 4 |
bbb = 0 |
| 5 |
ddd = 0 |
#嵌套函數
def foo():
def func1():
pass
func1()#decorator進階
def auth(auth_type):
print("auth func:",auth_type)
def out_wrapper(func):
def wrapper(*args, **kwargs):
pass
return wrapper
return out_wrapper
@auth(auth_type = "local")
def form_page():
pass
| 函數 |
註解 |
| Iterable |
判斷是否能夠迭代,回傳True or False |
| Iterator |
判斷是否是Iterator對象,回傳True or False |
from collections import Iterable
print(isinstance([],Iterable))
print(isinstance({},Iterable))
print(isinstance('abc',Iterable))
print(isinstance(123,Iterable))
'''
生成器可以被next調用並不斷返回下一個值的對象稱為迭代器:Iterator
可以使用isinstance()判斷是否是Iterator對象。
'''
from collections import Iterator
print(isinstance((x for x in range(10)),Iterator))
| 函數 |
註解 |
| .next() |
查詢,查詢之前不會產生所以用next查詢時才會產生 |
比一般產生的速度和佔容量大小更優秀
# 生成器的方式返回的是一個公式的地址
a = (i * 3 for i in range(10000000))
# 一般定義的列表
a = [i * 3 for i in range(10000000)]
| 函數 |
註解 |
| json.dumps |
轉為json字典格式 |
| pickle.dump |
轉為二進制 |
| pickle.load |
等同於pickle.loads(f.read()) |
| 函數 |
註解 |
| filter |
過濾 |
| map |
個別運算 |
| [x * 2 for x in range(10)] |
產生列表 |
| functools.reduce(lambda x, y: x + y, range(3)) |
累加 |
| divmod |
相除取商和餘數 |
| sorted(a.items()) |
依照key排序 |
| sorted(a.items(), key=lambda x: x[1])) |
依照value排序 |
| for i, k in zip(a, b): |
兩個元素對應,拼接 |
| map(square, [1, 2, 3, 4, 5]) |
map 在一個可以迭代的(iterable)的元素,遍歷使用函數 |
| 函數 |
註解 |
| time.mktime(time.gmtime()) |
將struct_time格式轉為時間戳 |
| time.gmtime() |
公元時間 |
| time.localtime() |
本地時間 |
| time.localtime().tm_year |
獲取年 |
| time.strftime("格式", 時間) |
struct_time格式轉換成你想要的時間格式 |
| time.strptime(時間, "格式") |
依照提供的時間,對應轉換的格式,轉回struct_time的格式 |
| ime.asctime() |
接受元組tuple格式 |
| time.ctime() |
接受時間戳格式 |
| 函數 |
註解 |
| os.path.dirname('PATH') |
查找這個'PATH'的目錄名稱 |
os.path.abspath(__file__)) |
執行當下的絕對路徑 |
| print(os.getcwd()) |
獲取執行檔的當前目錄 |
os.chdir('/dir/path'),os.chdir('..') |
前往目錄 |
| print(os.listdir(os.getcwd())) |
查詢一個目錄下的所有目錄與檔案,包含隱藏檔案 |
| print(os.sep) |
相當於windows下的\\,linux下的/ |
| print(os.path.split('/user/a/c/a.txt')) |
切割目錄和檔名 |
print(os.path.exists('/Users/leon/PycharmProjects/practice/老男孩python/')) |
目錄是否存在,True or False |
| os.path.join('/usr', '/abc') |
目錄合併, join的操作不只在os模塊 |
os.mkdir('\\a') |
創建一個目錄 |
os.rmdir('\\a') |
刪除一個目錄 |
| os.pardir |
獲取當前目錄的上一層(父目錄) |
| os.curdir |
獲取當前目錄 |
| os.listdir('.') |
顯示當前目錄 |
| os.remove() |
刪除一個文件 |
| os.rename('oldname','newname') |
重新命名檔案 |
os.makedirs(os.getcwd() + "\\a\\b\\c\\d") |
創建好幾層目錄(ex:c:\a\b\c\d),即使沒有b,c,d也能一次創建' |
os.removedirs(os.getcwd() + "\\a\\b\\c\\d") |
移除dirs,若目錄為空則刪除,如果有文件則不刪除,用於刪除空目錄的 |
| os.environ |
環境變數 |
os.name |
顯示當前使用的os, win顯示nt , linux顯示posix :', |
| os.system('ping 8.8.8.8 -t 1') |
cmd指令 |
$ python test.py # 此時 __file__ 是 test.py
$ python ../test.py # 此時 __file__ 是 ../test.py
$ python hello/../test.py # 此時 __file__ 是 hello/../test.py
| 函數 |
註解 |
| random.random() |
隨機0~1 浮點數 |
| random.uniform(1, 2) |
可自己設定浮點數區間 |
| random.randint(1, 7) |
隨機1~7 整數, 包含7 |
| random.randrange(7) |
range 顧頭不顧尾, 0~7的範圍, 不包含7 |
| random.choice('hello') |
隨機選擇可傳入可遞歸的東西,'字串',[1,2,3],["hello"] ,'字串',[1,2,3] |
| random.sample('hello', 2) |
可在後面設定要取幾位 |
| random.shuffle(list_a) |
洗牌功能(範例看這) |
| 函數 |
註解 |
| pickle.dumps(data) |
將數據以特殊型式轉換為python語言認識的字符串 |
| pickle.dump(data,f) |
用pickle格式,寫入f檔案 |
| json.dumps(data) |
將數據以特殊型式轉換為所有語言認識的字符串 |
| json.dump(data,f) |
用json格式,寫入f檔案 |
import pickle, json
data1 = {'k1': 123, 'k2': 'hello'}
p_str = pickle.dumps(data1) # 將數據以特殊型式轉換為python語言認識的字符串
print(p_str)
# with open('pickle.pk','w') as pf: #pickle 寫入文件
# pickle.dump(data1,pf)
j_str = json.dumps(data1) # 將數據以特殊型式轉換為所有語言認識的字符串
print(j_str)
# with open('json.json','w') as jf: #json 寫入文件
# json.dump(data1,jf)b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01K{X\x02\x00\x00\x00k2q\x02X\x05\x00\x00\x00helloq\x03u.'
{"k1": 123, "k2": "hello"}
寫程式的時候如果不想用關聯式資料庫那麼重量級的東東去儲存資料,不妨可以試試用shelve,也是使用key,value來儲存
#寫入
import shelve
s = shelve.open('test_shelf.db')
try:
s['key1'] = { 'int': 10, 'float':9.5, 'string':'Sample data' }
finally:
s.close()#讀取
import shelve
s = shelve.open('test_shelf.db')
try:
existing = s['key1']
finally:
s.close()
print (existing) #印出結果{'int': 10, 'float': 9.5, 'string': 'Sample data'}
| 函數 |
註解 |
| shutil.copyfileobj(f1, f2) |
copy 內容 |
| shutil.copyfile('shutil_note2', 'shutil_note3') |
copy文件 |
| shutil.copytree('old_dir','new_dir') |
遞歸的複製目錄 #olddir和newdir都只能是目录,且newdir必须不存在 |
| shutil.rmtree('new_dir') |
遞歸移除目錄 |
| shutil.move('/sss/aaa.txt','/new_dir') |
移動文件 |
| shutil.make_archive('shutil_archive', 'zip', '/dir/dir') |
用shutil壓縮文件 |
| zipfile.ZipFile('day5.zip', 'w') |
打包 壓縮 zip ,打包不壓縮 tar |
import zipfile
z = zipfile.ZipFile('day5.zip', 'w')
z.write('shutil_note1') # 指定要壓縮的檔案
print('-------') # 中間可以做別的事情
z.write('shutil_note2')
z.close()
# 解壓
z = zipfile.ZipFile('day5.zip','r')
z.extractall()
z.close()
| 函數 |
註解 |
| sys.version |
查看python版本 |
| sys.maxsize |
系統容量 |
| sys.exit(0) |
正常退出程序 |
import sys, time
# 之前的進度條
for i in range(10):
sys.stdout.write('*')
sys.stdout.flush()
time.sleep(0.1)
| 函數 |
註解 |
| hashlib.md5() |
|
| m.hexdigest()) #hex格式加密 |
|
| hashlib.sha1() |
|
| hmac.new(b'string', b'string2') |
|
import xml.etree.ElementTree as ET
import xml.etree.ElementTree as ET
new_xml = ET.Element('namelist')
name = ET.SubElement(new_xml, 'name', attrib={"enrolled":"yes"})
age = ET.SubElement(name, 'age', attrib={"checked":"no"})
sex = ET.SubElement(name, 'sex')
sex.text = '30'
name2 = ET.SubElement(new_xml, 'name', attrib={"enrolled":"no"})
age = ET.SubElement(name2, 'age')
age.text = '20'
et = ET.ElementTree(new_xml) # 生成文檔對象
et.write('0414_test.xml', encoding='utf-8', xml_declaration=True) #xml_declaration:聲明是xml格式的文檔
ET.dump(new_xml) #打印生成的格式import xml.etree.ElementTree as ET
tree = ET.parse('0414_xml.xml')
root = tree.getroot()
print(root.tag)
for child in root: ## 遍歷root
print('child.tag:{} ,child.attrib:{}'.format(child.tag, child.attrib))
for i in child:
print('i.tag:{} ,i.text:{} ,child.attrib:{}'.format(i.tag, i.text, i.attrib))
for node in root.iter('year'): # 遍歷單一節點
print(node.tag, node.text)import xml.etree.ElementTree as ET
tree = ET.parse('0414_xml.xml')
root = tree.getroot()
# 修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set('update', 'yes')
tree.write('0414_xml.xml')
# 刪除
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('0414_output.xml')
| 中文 |
英文 |
| 類別 |
class |
| 對象 |
object |
| 封裝 |
Encapsulation |
| 繼承 |
Inheritance |
| 多態 |
polymorphism |
| 靜態方法 |
@staticmethod |
| 類方法 |
@classmethod |
| 屬性方法 |
@property |
| 反射 |
hasattr,getattr,setattr,delattr |
python2 經典類class 繼承是按深度優先繼承, 新型類是依照廣度優先繼承
python3 經典類與新型類都是依照廣度優先繼承
| 函數 |
註解 |
self.name = name |
實例變量(靜態屬性),作用域就是實例本身 |
| self.__life_value = 100 |
私有屬性 |
def shot(self): |
類的方法, 功能(動態屬性) |
def __init__(self, name) |
構造函數 |
def __new__(cls, *args, **kwargs): |
會比init還早做完,所以必須要做return的動作才會調用到__init__ |
print("Foo --new--")
return object.__new__(cls) #如果沒有return就不會接著做init(實例化)
def __del__(self):| 析構函數(一定是最後才做的,用於實例釋放或銷毀的時候自動執行的,通常用於做一些收尾工作,如關閉一些數據庫鏈接、打開的臨時文件)
def __getitem__(self, key):| result = obj['k1'] #自動觸發執行 __getitem__
def __setitem__(self, key):|# obj['k2'] = "alex" #自動觸發執行 __setitem__
def __delitem__(self, key):| del obj['ddddd'] # 沒有ddddd也不會報錯 ,意思是使用字典去調用而已
a = class_name('Leon')|實例化
r1.bullet_prove = True | 沒有的變數也可以在這邊生成
del r1.weapon | 刪除變數
r1.n = '456' | 修改r1的n
class Foo:
'''描述這個類Foo是做什麼用的'''
print("印出Foo的描述說明:", Foo.__doc__)
print("class.__dict__:",Foo.__dict__) #打印類裡的所有屬性,不包含實例屬性
print("b.__dict__:",b.__dict__) #只顯示實際產生的屬性,不包含類屬性
print("module:", c.__module__) # 輸出模塊
print("class:", c.__class__) # 輸出類
| 函數 |
註解 |
class Man(People): |
繼承父親(People)的東西 |
People.__init__(self, name, age) |
繼承的方法ㄧ |
super(Man, self).__init__(name, age) |
繼承的方法二 |
| 函數 |
註解 |
def animal_talk(obj): |
多態的性質:一個接口 |
| 函數 |
註解 |
| @staticmethod |
靜態方法裝飾後實際上跟類沒什麼關係,把它當作一個單純的函數 |
| 函數 |
註解 |
| @property |
屬性方法 |
| @foo.setter |
賦值 |
| @foo.deleter |
foo想刪除food |
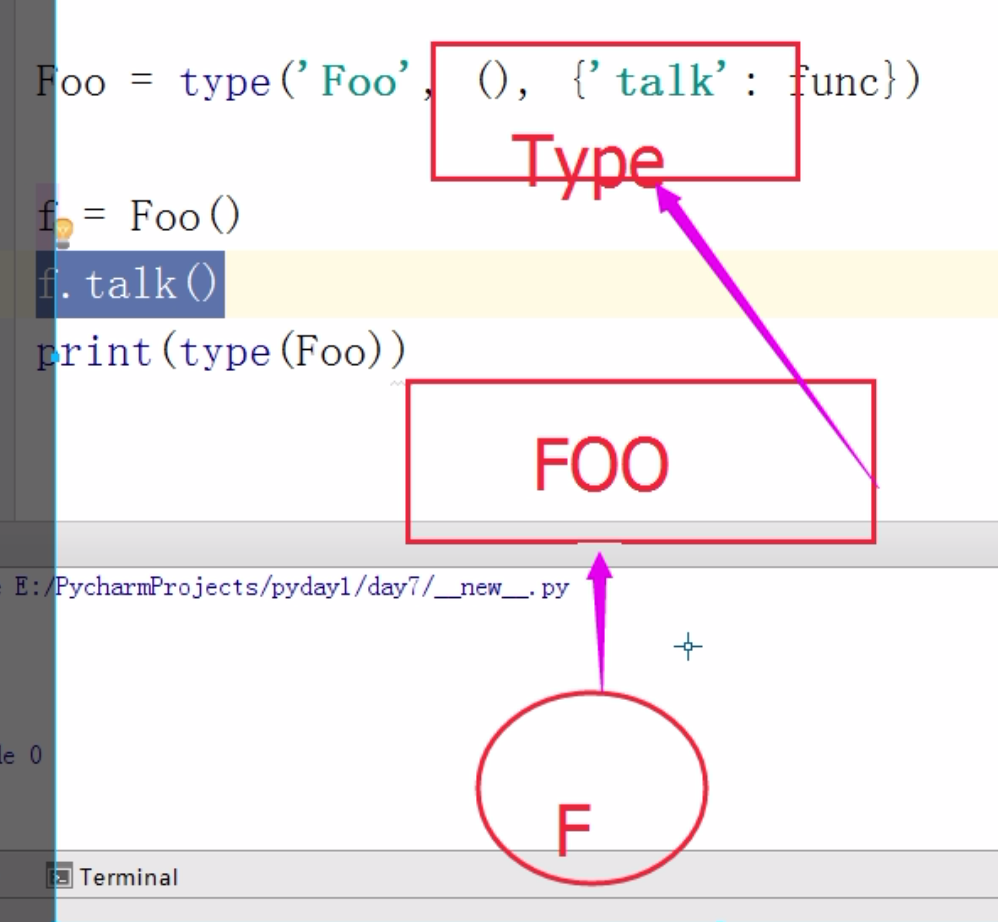
創建class, 一個Foo對象
(object,) <~必須加逗點,因為他是元祖的形式,
你不加一個逗點他就把它當作一個值了,加了逗點他才知道你是元祖的形式
Foo = type("Foo", (object,), {"talk": func, "__init__": initt})
| 錯誤類型 |
註解 |
| KeyError |
字典的key操作錯誤 |
| IndexError |
陣列的操作錯誤 |
| TypeError |
型態錯誤 |
| ValueError |
型態操作錯誤 , s1 = "s" ,int(s1) |
| Exception |
大宗錯誤 |
# 自定義異常
class leonException(Exception):
def __init__(self, msg):
self.message = msg
self.sss = msg + "234"
def __str__(self): # __str__ 用於定義返回的值為什麼格式
return self.message
# return '我是異常例外喔'
try:
raise leonException('我的異常') # raise (瑞斯) 觸發的意思
except leonException as e:
print(e)如果遇到動態import的情況,需要用字串來import的話
# from 0702module import aa
# 如果遇到動態import的情況,需要用字串來import的話
# import_from = input("請輸入你要improt的東西:").strip()
# import_from2 = input("請輸入你要improt的東西:").strip()
import_from = "0702module.aa"
import_from2 = 'zxc'
c = __import__(import_from, fromlist=[import_from2])
if hasattr(c, import_from2):
func = getattr(c, import_from2)
print(func)
# 官方建議用法
import importlib
import_from = "0702module.aa"
import_from2 = 'zxc'
b = importlib.import_module(import_from)
if hasattr(b, import_from2):
func = getattr(b, import_from2)
print(func)